Nvidia Nemotron 3 Super: Hybrid AI Cuts Costs 7.5x
Multi-agent AI systems generate 15x more tokens than standard chats, threatening enterprise budgets. Nvidia's new Nemotron 3 Super hybrid model solves this with breakthrough efficiency gains.
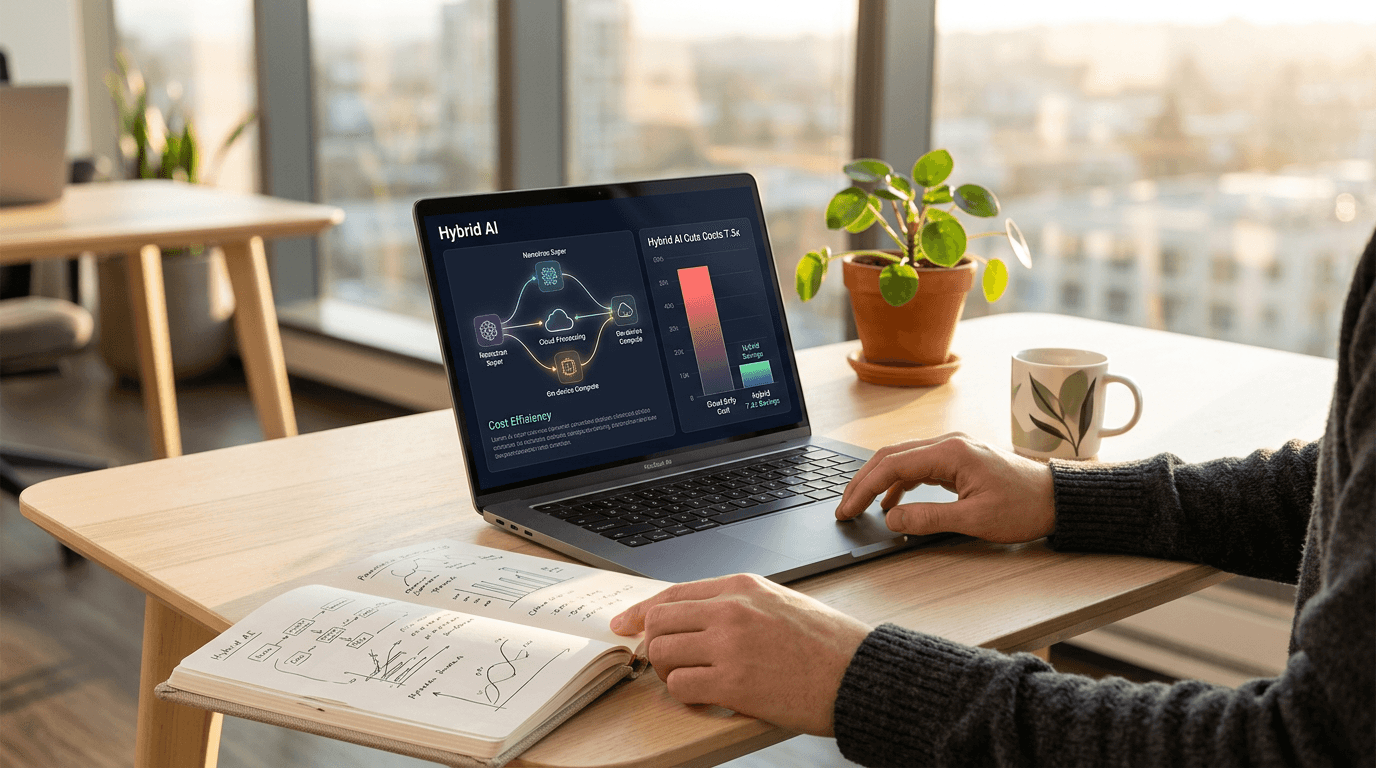
Multi-Agent AI Systems Are Draining Enterprise Budgets—Here's the Solution
Learn more about why crude oil prices keep rising despite record release
Multi-agent AI systems are creating a cost crisis for enterprises. These sophisticated systems, designed for complex tasks like software engineering and cybersecurity triaging, generate up to 15 times the token volume of standard chatbots. For businesses scaling AI operations, this "context explosion" translates directly into unsustainable infrastructure costs.
Nvidia's response arrived today with Nemotron 3 Super, a 120-billion-parameter hybrid model that promises to solve the enterprise AI efficiency problem. By merging three distinct architectural approaches, the company aims to deliver specialized depth for agentic workflows without the computational bloat typical of dense reasoning models.
What Makes Nvidia Nemotron 3 Super Different from Traditional AI Models?
Nemotron 3 Super breaks from traditional AI architecture by combining three disparate design philosophies into a single model. This represents a fundamental rethinking of how enterprise AI should handle long-horizon tasks.
The model's 120 billion parameters operate under a mostly open weights license, making it commercially available for businesses seeking alternatives to proprietary solutions. Nvidia posted the weights on Hugging Face, signaling a strategic shift toward collaborative enterprise AI development.
The Triple Hybrid Architecture Explained
Nemotron 3 Super uses a Hybrid Mamba-Transformer backbone at its core. This architecture interleaves Mamba-2 layers with strategic Transformer attention layers, creating a balance between memory efficiency and precision reasoning.
Mamba-2 layers function as a highway system for data processing. They handle the vast majority of sequence processing with linear-time complexity, allowing the model to maintain a massive 1-million-token context window. This solves the "needle in a haystack" problem where AI must locate specific information buried within enormous datasets.
Pure state-space models struggle with associative recall. Nvidia addresses this weakness by inserting Transformer attention layers as "global anchors." These layers ensure the model can precisely retrieve specific facts from deep within codebases or financial reports.
How Does Latent Mixture-of-Experts Reduce Operational Costs?
For a deep dive on apple tv academy awards: complete oscar winners & nominees, see our full guide
Traditional Mixture-of-Experts (MoE) designs route tokens to specialists in their full hidden dimension. This creates computational bottlenecks as models scale, directly impacting operational costs for enterprises running high-volume workloads.
Nemotron 3 Super introduces Latent Mixture-of-Experts (LatentMoE), which projects tokens into compressed space before routing them to specialists. This "expert compression" allows the model to consult four times as many specialists for the same computational cost.
For a deep dive on baochip-1x: what it is and why it matters now, see our full guide
For business applications, this granularity matters enormously. AI agents must switch between Python syntax, SQL logic, and conversational reasoning within single interactions. LatentMoE enables this flexibility without proportional cost increases.
Why Multi-Token Prediction Accelerates Production Workflows
Standard AI models predict one next token at a time. Nemotron 3 Super uses Multi-Token Prediction (MTP) to predict several future tokens simultaneously, functioning as a "built-in draft model."
This approach enables native speculative decoding, delivering up to 3x wall-clock speedups for structured generation tasks. For enterprises generating code or processing tool calls at scale, these speedups translate directly into reduced infrastructure costs and faster time-to-value.
How Does Blackwell GPU Optimization Benefit Enterprise Deployment?
Nvidia optimized Nemotron 3 Super specifically for its Blackwell GPU platform. By pre-training natively in NVFP4 (4-bit floating point), the company achieved a breakthrough in production efficiency that matters for enterprise budgets.
On Blackwell hardware, the model delivers 4x faster inference than 8-bit models running on the previous Hopper architecture. This speed increase comes with no accuracy loss, eliminating the traditional tradeoff between performance and precision.
Real-World Performance Benchmarks
Nemotron 3 Super currently holds the top position on DeepResearch Bench, measuring AI's ability to conduct thorough, multi-step research across large document sets. This benchmark directly reflects the model's suitability for enterprise knowledge work.
The throughput advantages prove substantial in production environments. Nemotron 3 Super achieves up to 2.2x higher throughput than gpt-oss-120B and 7.5x higher than Qwen3.5-122B in high-volume settings. For businesses processing thousands of agent interactions daily, these multipliers represent significant cost savings.
In coding tasks, the model scored 60.47% on SWE-Bench using OpenHands, demonstrating practical software engineering capabilities. Its performance on RULER benchmarks shows impressive context handling: 96.30% at 256k tokens, 95.67% at 512k tokens, and 91.75% at 1 million tokens.
What Does the Commercial License Structure Allow?
Nvidia released Nemotron 3 Super under its Open Model License Agreement (updated October 2025). This license provides a permissive framework for enterprise adoption but includes distinct "safeguard" clauses differentiating it from pure open-source licenses.
What Can Businesses Do With This Model?
The license grants explicit commercial usability with a perpetual, worldwide, royalty-free framework. Enterprises can sell and distribute products built on the model without ongoing licensing fees.
Nvidia makes no claim to outputs generated by the model. Responsibility and ownership of those outputs rest entirely with users, a critical consideration for businesses building proprietary applications.
Companies can create and own "Derivative Models" through fine-tuning, provided they include required attribution: "Licensed by Nvidia Corporation under the Nvidia Open Model License."
What Are the Critical License Restrictions?
Two termination triggers require careful monitoring. The license automatically terminates if users bypass the model's safety guardrails without implementing substantially similar replacements appropriate for their use case.
Additionally, instituting copyright or patent litigation against Nvidia alleging model infringement triggers immediate license termination. This structure protects Nvidia from IP disputes while fostering a commercial ecosystem.
How Are Enterprises Integrating Nemotron 3 Super?
The developer community response has been enthusiastic. Chris Alexiuk, Senior Product Research Engineer at Nvidia, emphasized the release includes not just weights but 10 trillion tokens of training data and recipes, unprecedented transparency for a commercial model.
Cloud and On-Premises Deployment Options
Nvidia is deploying the model as a NIM microservice, enabling flexible deployment options. Enterprises can run it on-premises via Dell AI Factory or HPE infrastructure, maintaining data sovereignty and security.
Cloud availability spans Google Cloud and Oracle immediately, with AWS and Azure support coming shortly. This multi-cloud strategy prevents vendor lock-in, a key concern for enterprise AI buyers.
Which Companies Are Already Using Nemotron 3 Super?
CodeRabbit and Greptile are integrating the model for large-scale codebase analysis, addressing the software development bottleneck many enterprises face. Industrial leaders including Siemens and Palantir are deploying it to automate complex workflows in manufacturing and cybersecurity.
These early adopters represent sectors where AI agent costs threatened project viability. Their adoption signals that Nemotron 3 Super's efficiency gains translate into real business value.
What Are the Strategic Implications for Enterprise AI?
Kari Briski, Nvidia VP of AI Software, framed the challenge succinctly: "As companies move beyond chatbots and into multi-agent applications, they encounter context explosion." This context explosion represents the primary barrier to scaling enterprise AI beyond pilot projects.
Nemotron 3 Super provides the computational power of a 120B parameter system with operational efficiency approaching much smaller specialist models. For CFOs evaluating AI investments, this efficiency shift changes the ROI calculus fundamentally.
The "thinking tax" that made multi-agent systems prohibitively expensive for many use cases is finally decreasing. Enterprises can now consider AI applications previously dismissed as too costly to operate at scale.
Key Takeaways for Business Leaders
Nvidia's Nemotron 3 Super represents a strategic inflection point for enterprise AI economics. The hybrid architecture combining state-space models, transformers, and Latent MoE delivers 7.5x throughput improvements over competing models.
The Blackwell optimization providing 4x faster inference without accuracy loss makes previously marginal AI projects financially viable. Combined with the mostly open weights license, enterprises gain unprecedented flexibility in deployment and customization.
Continue learning: Next, explore 20x signal boost: new brain blood flow monitoring breakth...
For businesses evaluating multi-agent AI systems, Nemotron 3 Super offers a credible path forward. The model addresses the cost explosion threatening enterprise AI adoption while maintaining the specialized depth required for complex workflows. As AI moves from experimentation to production at scale, efficiency innovations like this will separate successful implementations from expensive failures.
Related Articles
Nous Research Launches Hermes 4 AI: Outperforming ChatGPT
Nous Research unveils Hermes 4 AI models that surpass ChatGPT, offering uncensored responses and advanced reasoning. Explore their impact on businesses.
Sep 17, 2025

How Intuit Reinvented AI: A Playbook for Businesses
Explore how Intuit reinvented its approach to AI, moving from chatbots to an agentic AI playbook that businesses can replicate.
Sep 12, 2025

OpenAI Enhances Voice AI for Enterprise with GPT-Realtime
OpenAI's gpt-realtime sets a new voice AI standard with naturalistic voices and advanced capabilities, aiming to transform enterprise applications.
Sep 10, 2025